---
title: "Did Authors Respond to Unjournal Evaluations?"
author: "The Unjournal"
date: last-modified
format:
html:
toc: true
toc-depth: 3
code-fold: true
code-summary: "Show code"
execute:
echo: true
warning: false
message: false
freeze: auto
---
::: {.content-visible when-format="pdf"}
The interactive tables in this appendix are available in the online version at <https://valentinklotzbuecher.github.io/llm-uj-research-eval/paper_response_analysis.html>.
:::
::: {.callout-note}
57 Unjournal evaluations tracked as of April 2026, drawing on two evidence streams: (a) manual staff assessment of author responses and paper revisions; (b) Claude Opus 4.6 change-attribution for 8 papers where pre/post PDFs were available. See [Combined Evidence](#combined-evidence) below.
:::
## Overview
The Unjournal commissions open, structured evaluations of working papers in economics and social science. A natural question is whether this process changes research: do authors engage with feedback and revise their work?
This page draws on manual classification of 57 tracked evaluations and, for a subset, automated PDF diffing and LLM attribution. Background: [The Unjournal's knowledge base](https://globalimpact.gitbook.io/the-unjournal-project-and-communication-space/benefits-and-features/more-reliable-and-useful-evaluation/author-engagement-evidence).
```{r}
#| label: setup
#| code-summary: "Load data and define helpers"
library(dplyr)
library(ggplot2)
library(readr)
library(DT)
library(tidyr)
library(stringr)
library(glue)
library(jsonlite)
df <- read_csv("data/author_adjustment_manual.csv", show_col_types = FALSE)
df <- df |>
rename(
paper_title = label_paper_title,
pubpub_link = dup_pubpub_final_links,
adj_status = `Adjusted_paper?`,
updated_manual = `Updated since UJ report -- manual confirmation`,
deposit_after = `deposit date > unjournal pub date`,
research_area = main_cause_cat_abbrev,
nb_link = notebookLM_link,
pub_status = publication_status,
wp_date = working_paper_release_date,
uj_pub_date = publication_date_unjournal
)
adj_labels <- c(
"Evidence of updating", "Stated intention to update",
"Mixed / minor updating", "Unlikely to update", "Not yet assessed"
)
df <- df |>
mutate(
adj_status_clean = case_when(
adj_status == "evidence of updating" ~ "Evidence of updating",
adj_status == "Stated intention to update" ~ "Stated intention to update",
adj_status == "mixed evidence/minor updating" ~ "Mixed / minor updating",
adj_status == "Unlikely to update" ~ "Unlikely to update",
TRUE ~ "Not yet assessed"
),
adj_status_clean = factor(adj_status_clean, levels = adj_labels),
author_response_clean = case_when(
author_response == "Formal response" ~ "Formal response",
author_response == "Informal" ~ "Informal response",
author_response == "None?" ~ "No response",
TRUE ~ "Not yet coded"
)
)
theme_uj <- function(base_size = 12) {
theme_minimal(base_size = base_size) +
theme(panel.grid.minor = element_blank(),
axis.text = element_text(size = base_size * 0.85),
plot.caption = element_text(size = base_size * 0.75, color = "grey50"),
legend.position = "right")
}
```
## Combined Evidence of Paper Updating {#combined-evidence}
Two evidence streams are combined: manual classification for all 57 papers, and Claude Opus 4.6 LLM attribution for 8 papers where before/after PDFs were available and meaningful text changes were detected.
::: {.callout-note collapse="true"}
## Pipeline and caveats
**Scripts**: `scripts/fetch_latest_papers.py` → `scripts/run_paper_change_llm.py`
- **Before version**: PDF sent to Unjournal evaluators (`papers/`); **After version**: latest NBER/arxiv version, fetched April 2026
- **Model**: Claude Opus 4.6, temperature 0.2; conservative instructions — only flags "direct" or "indirect" attribution with clear conceptual alignment to a specific evaluator suggestion
- **Coverage**: 30 papers had fetchable DOIs; 8 had meaningful changes (≥15 line edits or ≥0.5% size change) and a matched evaluation file; the 3 manually-confirmed updates were also LLM-analyzed
- **Temporal caveat**: a newer version does not imply changes were evaluation-driven; some papers were already in revision
- **LLM limitations**: text truncated at 60,000 chars/version; figures and tables not visible to the model
:::
```{r}
#| label: llm-attribution-load
#| code-summary: "Load and merge LLM + manual data"
nn <- function(x, default = NA) if (!is.null(x)) x else default
llm_results_path <- "data/paper_change_llm_results.json"
# Signal tier labels used throughout — define once
tier_levels <- c(
"Confirmed, LLM >=40%",
"Confirmed, LLM <40%",
"LLM >=30% (not confirmed)",
"LLM 10-29%",
"LLM <10%"
)
tier_colors_llm <- c(
"Confirmed, LLM >=40%" = "#1a7a47",
"Confirmed, LLM <40%" = "#2D9D5E",
"LLM >=30% (not confirmed)" = "#5AE08A",
"LLM 10-29%" = "#a8d5b5",
"LLM <10%" = "#d0e8d8"
)
if (file.exists(llm_results_path)) {
llm_raw <- fromJSON(llm_results_path, simplifyVector = FALSE)
llm_df <- lapply(llm_raw, function(r) {
oa <- r$overall_assessment
data.frame(
paper_title = nn(r$paper_title, ""),
adj_status_csv = nn(r$adj_status, ""),
deposit_after_uj = isTRUE(r$deposit_after_uj),
text_chg_pct = nn(r$text_length_change_pct, NA_real_),
additions = nn(r$additions_count, NA_integer_),
deletions = nn(r$deletions_count, NA_integer_),
n_major_changes = length(nn(r$major_changes, list())),
n_suggestions = length(nn(r$evaluator_suggestions, list())),
pct_influenced = if (!is.null(oa)) nn(oa$pct_likely_influenced, NA_real_) else NA_real_,
attr_confidence = if (!is.null(oa)) nn(oa$confidence, NA_real_) else NA_real_,
narrative = if (!is.null(oa)) nn(oa$narrative, "") else "",
eval_found = !is.null(r$eval_file) && nchar(nn(r$eval_file, "")) > 0,
skipped = !is.null(r$skipped_reason),
stringsAsFactors = FALSE
)
}) |> bind_rows()
llm_analyzed <- llm_df |>
filter(!skipped & eval_found & n_major_changes > 0 & !is.na(pct_influenced))
llm_enriched <- llm_analyzed |>
left_join(df |> select(paper_title, research_area, pubpub_link), by = "paper_title") |>
mutate(
manual_tier = case_when(
adj_status_csv == "evidence of updating" ~ "Confirmed update",
adj_status_csv == "Stated intention to update" ~ "Stated intention",
adj_status_csv == "mixed evidence/minor updating" ~ "Mixed / minor",
adj_status_csv == "Unlikely to update" ~ "Unlikely",
TRUE ~ "Unclassified"
),
combined_tier = case_when(
manual_tier == "Confirmed update" & pct_influenced >= 40 ~ tier_levels[1],
manual_tier == "Confirmed update" ~ tier_levels[2],
pct_influenced >= 30 ~ tier_levels[3],
pct_influenced >= 10 ~ tier_levels[4],
TRUE ~ tier_levels[5]
),
combined_tier = factor(combined_tier, levels = tier_levels)
)
n_analyzed <- nrow(llm_enriched)
n_total_fetched <- nrow(llm_df)
med_pct <- median(llm_enriched$pct_influenced, na.rm = TRUE)
n_high <- sum(llm_enriched$pct_influenced >= 30, na.rm = TRUE)
} else {
llm_df <- llm_analyzed <- llm_enriched <- data.frame()
n_analyzed <- n_total_fetched <- n_high <- 0
med_pct <- NA_real_
}
```
```{r}
#| label: llm-attribution-summary
#| results: asis
#| code-summary: "Summary"
if (nrow(llm_enriched) > 0) {
n_confirmed <- sum(llm_enriched$manual_tier == "Confirmed update")
n_llm_high <- sum(llm_enriched$manual_tier == "Unclassified" &
llm_enriched$pct_influenced >= 30)
cat(glue::glue(
"Of {n_total_fetched} papers with fetchable DOIs, {n_analyzed} had meaningful text ",
"changes and a matched evaluation. {n_confirmed} are manually confirmed updates; ",
"of the remaining {n_analyzed - n_confirmed}, the LLM finds {n_llm_high} with at least 30% ",
"of changes likely driven by evaluator feedback (median across all: {round(med_pct)}%)."
))
}
```
```{r}
#| label: fig-combined-waffle
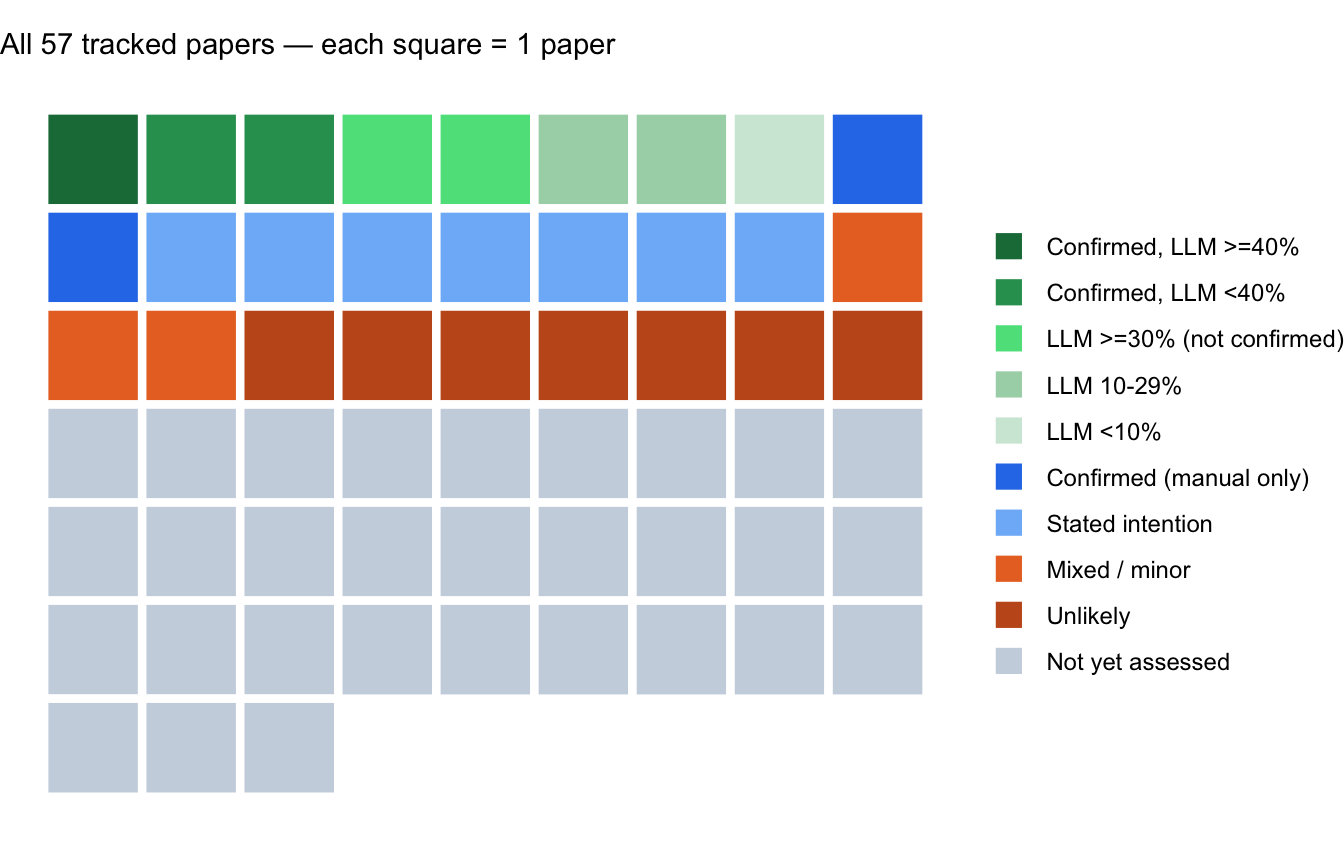
#| fig-cap: "All 57 tracked papers by combined evidence tier (each square = 1 paper). Green tones: papers where LLM analysis was run, shaded by attribution score and manual confirmation status. Blue: manually confirmed updates without LLM analysis. Orange/grey: stated intention, weak signal, or not yet assessed."
#| fig-height: 4.5
if (nrow(llm_enriched) > 0) {
# Build one row per paper with tier assignment
waffle_llm <- llm_enriched |>
select(paper_title, combined_tier) |>
mutate(group = as.character(combined_tier))
waffle_manual <- df |>
filter(!paper_title %in% llm_enriched$paper_title) |>
mutate(group = case_when(
adj_status_clean == "Evidence of updating" ~ "Confirmed (manual only)",
adj_status_clean == "Stated intention to update" ~ "Stated intention",
adj_status_clean == "Mixed / minor updating" ~ "Mixed / minor",
adj_status_clean == "Unlikely to update" ~ "Unlikely",
TRUE ~ "Not yet assessed"
)) |>
select(paper_title, group)
waffle_all_groups <- c(tier_levels,
"Confirmed (manual only)", "Stated intention",
"Mixed / minor", "Unlikely", "Not yet assessed")
waffle_colors <- c(
tier_colors_llm,
"Confirmed (manual only)" = "#2B7CE9",
"Stated intention" = "#7EB8F7",
"Mixed / minor" = "#E8722A",
"Unlikely" = "#C45A1E",
"Not yet assessed" = "#CBD5E1"
)
waffle_data <- bind_rows(waffle_llm, waffle_manual) |>
mutate(group = factor(group, levels = waffle_all_groups)) |>
arrange(group) |>
mutate(rank = row_number(),
x = (rank - 1) %% 9,
y = -((rank - 1) %/% 9))
ggplot(waffle_data, aes(x = x, y = y, fill = group)) +
geom_tile(color = "white", linewidth = 1.5) +
coord_equal() +
scale_fill_manual(values = waffle_colors, name = NULL,
drop = FALSE) +
theme_void() +
theme(legend.position = "right",
legend.text = element_text(size = 9),
plot.title = element_text(size = 11, face = "plain",
margin = margin(b = 6))) +
labs(title = "All 57 tracked papers — each square = 1 paper")
}
```
```{r}
#| label: fig-combined-dot
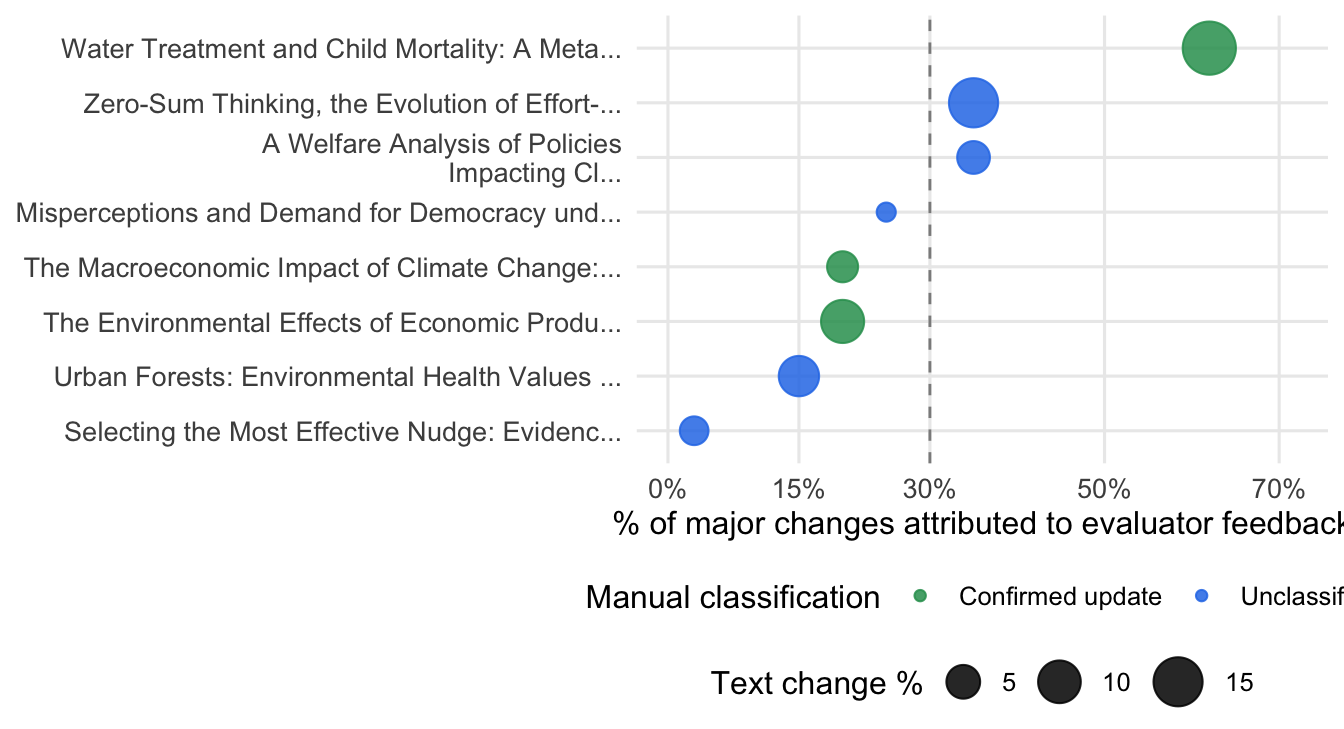
#| fig-cap: "LLM attribution for the 8 papers with pre/post versions compared. x-axis: estimated % of major changes attributed to evaluator feedback (Claude Opus 4.6, conservative). Point size scales with text change magnitude. Green = manually confirmed update; blue = not yet manually classified. Dashed line at 30%."
#| fig-height: 3.8
if (nrow(llm_enriched) > 0) {
dot_colors <- c("Confirmed update" = "#2D9D5E", "Unclassified" = "#2B7CE9")
llm_enriched |>
mutate(paper_short = str_trunc(paper_title, 46)) |>
ggplot(aes(x = pct_influenced, y = reorder(paper_short, pct_influenced),
color = manual_tier, size = text_chg_pct)) +
geom_vline(xintercept = 30, linetype = "dashed", color = "grey55", linewidth = 0.5) +
geom_point(alpha = 0.85) +
scale_color_manual(values = dot_colors, name = "Manual classification") +
scale_size_continuous(range = c(3, 9), name = "Text change %") +
scale_x_continuous(limits = c(0, 72), labels = \(x) paste0(x, "%"),
breaks = c(0, 15, 30, 50, 70)) +
labs(x = "% of major changes attributed to evaluator feedback", y = NULL) +
theme_uj() +
theme(legend.position = "bottom", legend.box = "vertical",
legend.margin = margin(0, 0, 0, 0))
}
```
```{r}
#| label: tbl-llm-attribution
#| tbl-cap: "Papers with LLM attribution results, sorted by % of changes attributed to evaluator feedback. 'Confirmed' = manually verified by Unjournal staff. Signal tier: 'Confirmed, LLM >=40%' = manually confirmed AND LLM finds strong corroboration; 'Confirmed, LLM <40%' = confirmed but weaker LLM signal; 'LLM >=30% (not confirmed)' = unconfirmed but LLM finds likely influence."
#| code-summary: "Combined evidence table"
#| eval: !expr knitr::is_html_output()
if (nrow(llm_enriched) > 0) {
tier_bg <- c(
"Confirmed, LLM \u226540%" = "#c8e6c9",
"Confirmed, LLM <40%" = "#d4edda",
"LLM \u226530% (not confirmed)" = "#e8f5e9",
"LLM 10\u201329%" = "#fff3e0",
"LLM <10%" = "#f8fafc"
)
tbl_llm <- llm_enriched |>
arrange(desc(pct_influenced)) |>
mutate(
Title = ifelse(
!is.na(pubpub_link) & nchar(pubpub_link) > 0,
paste0('<a href="', pubpub_link, '" target="_blank">',
str_trunc(paper_title, 60), '</a>'),
str_trunc(paper_title, 60)
),
`Manual` = manual_tier,
`LLM %` = paste0(round(pct_influenced), "%"),
`Conf.` = paste0(attr_confidence, "/5"),
`Signal tier` = combined_tier,
`LLM narrative` = str_trunc(narrative, 350)
) |>
select(Title, Manual, `LLM %`, Conf., `Signal tier`, `LLM narrative`)
datatable(
tbl_llm,
escape = FALSE,
rownames = FALSE,
options = list(
pageLength = 5,
dom = "tip",
scrollX = TRUE,
columnDefs = list(
list(width = "18%", targets = 0),
list(width = "11%", targets = 1),
list(width = "6%", targets = 2),
list(width = "5%", targets = 3),
list(width = "16%", targets = 4),
list(width = "44%", targets = 5)
)
)
) |>
formatStyle("Signal tier",
backgroundColor = styleEqual(names(tier_bg), unname(tier_bg)))
} else {
cat("*No LLM attribution results available yet.*")
}
```
## Summary Statistics
```{r}
#| label: summary-numbers
#| code-summary: "Compute headline statistics"
n_total <- nrow(df)
n_assessed <- df |> filter(adj_status_clean != "Not yet assessed") |> nrow()
n_evidence <- df |> filter(adj_status_clean == "Evidence of updating") |> nrow()
n_intention <- df |> filter(adj_status_clean == "Stated intention to update") |> nrow()
n_any_positive <- df |>
filter(adj_status_clean %in% c("Evidence of updating",
"Stated intention to update",
"Mixed / minor updating")) |> nrow()
n_formal <- df |> filter(author_response_clean == "Formal response") |> nrow()
n_any_resp <- df |>
filter(author_response_clean %in% c("Formal response", "Informal response")) |> nrow()
```
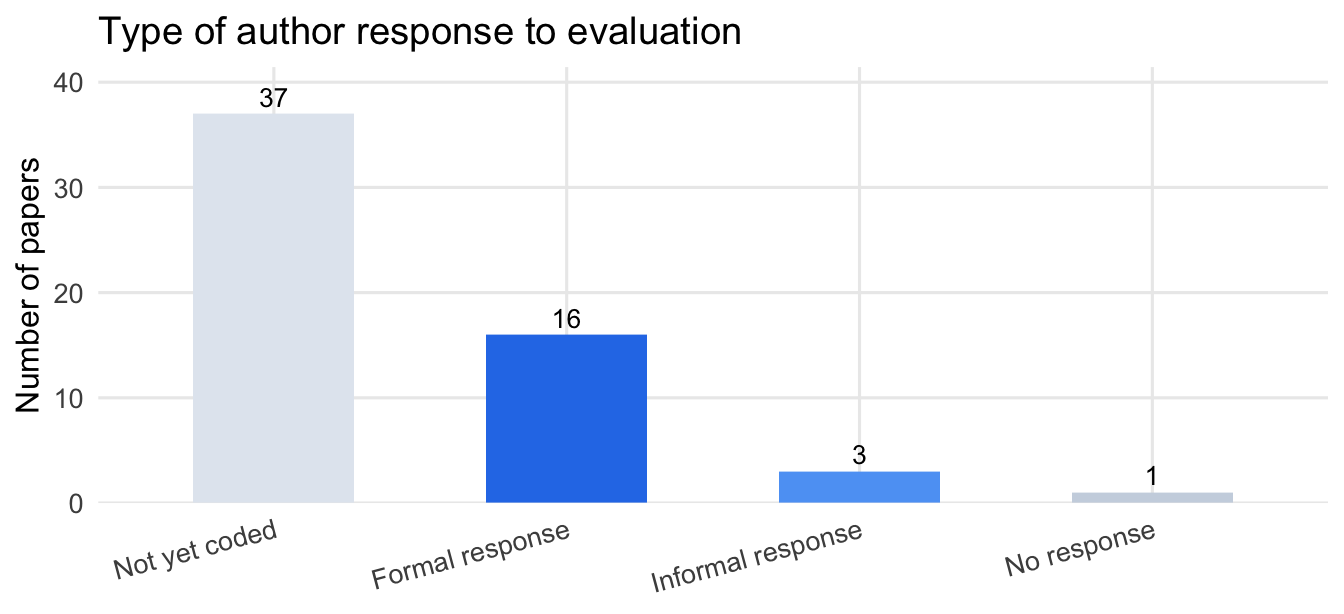
Of `r n_total` tracked evaluations, `r n_assessed` have been manually assessed. Among these: `r n_evidence` show clear evidence of substantive updating, `r n_intention` authors stated intention to update, and `r n_any_positive` show at least some positive signal. On engagement: `r n_any_resp` papers received a formal or informal author response, of which `r n_formal` were formal written responses.
```{r}
#| label: fig-response-bar
#| fig-cap: "Type of author response to Unjournal evaluation. 'Not yet coded' indicates the response status has not been assessed for those papers (37 blanks in data); this is distinct from confirmed non-response (only 1 paper is explicitly coded as no response)."
#| fig-height: 3.2
resp_colors <- c(
"Formal response" = "#2B7CE9",
"Informal response" = "#5DA3F5",
"No response" = "#CBD5E1",
"Not yet coded" = "#E2E8F0"
)
df |>
count(author_response_clean) |>
ggplot(aes(x = reorder(author_response_clean, -n), y = n,
fill = author_response_clean)) +
geom_col(width = 0.55, show.legend = FALSE) +
geom_text(aes(label = n), vjust = -0.4, size = 3.5) +
scale_fill_manual(values = resp_colors) +
scale_y_continuous(expand = expansion(mult = c(0, 0.12))) +
labs(x = NULL, y = "Number of papers",
title = "Type of author response to evaluation") +
theme_uj() +
theme(axis.text.x = element_text(angle = 15, hjust = 1))
```
## Full Tabulation
::: {.callout-note collapse="true"}
## All 57 tracked evaluations
Click column headers to sort; use the search box to filter. Adjustment status is color-coded: green = positive signal, orange = minor/uncertain, grey = unlikely or not yet assessed.
```{r}
#| label: tbl-full
#| code-summary: "Build interactive DT table"
#| eval: !expr knitr::is_html_output()
tbl <- df |>
mutate(
title_linked = if_else(
!is.na(pubpub_link) & pubpub_link != "",
paste0('<a href="', pubpub_link, '" target="_blank">',
str_trunc(paper_title, 72), '</a>'),
str_trunc(paper_title, 72)
),
authors_short = str_trunc(authors, 40),
nb_icon = if_else(
!is.na(nb_link) & nb_link != "",
paste0('<a href="', nb_link, '" target="_blank" title="NotebookLM">📖</a>'),
""
)
) |>
select(Paper = title_linked, Authors = authors_short,
Area = research_area, Response = author_response_clean,
Adjustment = adj_status_clean, `Pub.` = pub_status, NB = nb_icon)
adj_bg <- c(
"Evidence of updating" = "#d4edda",
"Stated intention to update" = "#e8f5e9",
"Mixed / minor updating" = "#fff3e0",
"Unlikely to update" = "#fce4d4",
"Not yet assessed" = "#f8fafc"
)
datatable(tbl, escape = FALSE, rownames = FALSE, filter = "top",
options = list(
pageLength = 8, autoWidth = FALSE, scrollX = TRUE, dom = "lfrtip",
columnDefs = list(
list(width = "36%", targets = 0),
list(width = "18%", targets = 1),
list(width = "8%", targets = 2),
list(width = "11%", targets = 3),
list(width = "16%", targets = 4),
list(width = "8%", targets = 5),
list(width = "3%", targets = 6)
)
),
caption = "All tracked Unjournal evaluations. NB = NotebookLM analysis link."
) |>
formatStyle("Adjustment",
backgroundColor = styleEqual(names(adj_bg), unname(adj_bg)))
```
:::